TabDSFidelity: Un Índice para Evaluar la Fidelidad de Datos Sintéticos Tabulares en Tareas de Clasificación.
Este trabajo propone "TabDSFidelity", una nueva función de calidad unificada para evaluar la fidelidad de los datos tabulares generados, tanto sintéticos como balanceados, en tareas de clasificación, siempre respecto a un conjunto de referencia original. TabDSFidelity integra la utilidad predictiva, la similitud de distribución y la preservación de correlaciones en una única puntuación ponderada y adaptable. La validación empleó diez conjuntos de datos reales de una Unidad de Cuidados Intensivos. Se generaron conjuntos balanceados mediante sobremuestreo y sintéticos, a gran escala, con SMOTE RSB* Adaptado con Ruido Gaussiano y CTGAN, seleccionando en cada etapa los óptimos con TabDSFidelity. Los resultados experimentales, utilizando diversos clasificadores, demuestran de manera consistente que los modelos entrenados con los datos seleccionados por TabDSFidelity superan significativamente en rendimiento a los entrenados con datos originales. Además, se encontró una correlación positiva y significativa entre las puntuaciones de TabDSFidelity y el rendimiento real de los modelos. En conclusión, TabDSFidelity se presenta como una herramienta efectiva y adaptable para la evaluación objetiva de la fidelidad de datos tabulares generados, facilitando la selección informada de conjuntos que optimizan el desempeño de modelos de clasificación.
Descripción de la función TabDSFidelity:
La función se calcula en tres etapas: primero, se obtienen métricas individuales como AUC-ROC, F1-score y Accuracy (entrenando un modelo Random Forest entrenado en datos balanceados o sintéticos y evaluandolo en el conjunto de referencia), Kolmogorov-Smirnov (para comparar distribuciones numéricas), Divergencias de Jensen-Shannon y Kullback-Leibler (para medir diferencias distribucionales en atributos numéricos y categóricos, respectivamente) y la media de la diferencia absoluta de la matriz de correlación de Pearson entre ambos conjuntos. Luego, se agregan las métricas (KS, JS, KL y C) mediante sumas específicas (las métricas de similitud de distribución y correlación se transforman para que valores más altos representen mayor calidad, sumando p-valores de Kolmogorov-Smirnov, invirtiendo las divergencias de Jensen-Shannon y Kullback-Leibler y el resultado de la similitud entre matrices de correlación), y se normalizan todas al rango [0,1] para mantener escalas comparables. Finalmente, se calcula la función de calidad TabDSFidelity como una combinación ponderada de estas métricas normalizadas:
TabDSFidelity = w_auc * AUC-ROC_norm + w_f1 * F1_norm + w_acc * Accuracy_norm + w_ks * KS_norm + w_js * JS_norm + w_kl * KL_norm + w_c * C_norm.
Conjuntos de Datos:
Los datos originales utilizados en este estudio fueron obtenidos a través de una aplicación web denominada "Generador de Conjuntos de Datos Dinámicos para el Servicio de Terapia Intensiva". Esta aplicación está diseñada para almacenar y gestionar información detallada de pacientes ingresados en Unidades de Cuidados Intensivos (UCI), permitiendo a los investigadores construir conjuntos de datos personalizados adaptados a sus necesidades específicas. Se generaron diez conjuntos de datos distintos (CD1 a CD10), cada uno correspondiente a una condición médica específica de pacientes ingresados en la UCI:
- CD1: Neumonía Grave Adquirida en la Comunidad.
- CD2: Enfermedad Pulmonar Obstructiva Crónica (EPOC) Exacerbada por Infección Respiratoria.
- CD3: Neumonía Nosocomial.
- CD4: Cetoacidosis Diabética.
- CD5: Contusión Cerebral.
- CD6: Hemorragia Subaracnoidea (HSA) Postraumática.
- CD7: Infección Urinaria.
- CD8: Meningoencefalitis Bacteriana.
- CD9: Síndrome de Weil.
- CD10: SPO de craniectomía y evacuación de Hematoma subdural.
Tabla 1. Características de los Conjuntos de Datos Originales del Caso de Estudio (UCI).
|
Conjunto de Datos |
No. de Ejem. |
No. de Atrib. |
No. Atrib. Cat. |
Proporción Clase Positiva ("Fallecido" = 1) |
Proporción de Desbalance |
Tipo de Desbalance |
|
CD1 |
548 |
24 |
20 |
0.30 |
2.36 |
Mínimo |
|
CD2 |
216 |
26 |
22 |
0.17 |
4.68 |
Severo |
|
CD3 |
548 |
21 |
17 |
0.30 |
2.36 |
Mínimo |
|
CD4 |
117 |
26 |
20 |
0.12 |
6.80 |
Severo |
|
CD5 |
206 |
20 |
16 |
0.32 |
2.12 |
Mínimo |
|
CD6 |
206 |
39 |
35 |
0.32 |
2.12 |
Mínimo |
|
CD7 |
239 |
33 |
29 |
0.37 |
1.68 |
Mínimo |
|
CD8 |
39 |
24 |
20 |
0.25 |
2.90 |
Mínimo |
|
CD9 |
69 |
34 |
30 |
0.26 |
2.83 |
Mínimo |
|
CD10 |
206 |
46 |
42 |
0.32 |
2.12 |
Mínimo |
|
Promedio Aproximado |
239 |
29 |
25 |
0.27 |
2.99 |
Mínimo |
Técnicas de Balanceo Empleadas:
- Random Oversampling.
- SMOTE (Synthetic Minority Oversampling Technique).
- Borderline SMOTE.
- ADASYN (Adaptive Synthetic Sampling Approach).
- SMOTE RSB* Adaptado con Restricciones del Dominio.
Tabla 2. Técnica de Sobremuestreo Óptima y su Rendimiento para el Conjunto de Datos Balanceado de "Mejor Fidelidad".
|
Conjunto de Datos |
Técnica de Sobremuestreo Óptima |
AUC-ROC |
F1-score |
Accuracy |
|
CD1 |
SMOTE RSB* Adaptado |
0.940 |
0.863 |
0.861 |
|
CD2 |
Sobremuestreo Aleatorio |
0.940 |
0.825 |
0.815 |
|
CD3 |
SMOTE RSB* Adaptado |
0.875 |
0.871 |
0.876 |
|
CD4 |
Sobremuestreo Aleatorio |
1.000 |
0.824 |
0.800 |
|
CD5 |
Sobremuestreo Aleatorio |
0.927 |
0.847 |
0.846 |
|
CD6 |
Sobremuestreo Aleatorio |
0.958 |
0.942 |
0.942 |
|
CD7 |
SMOTE RSB* Adaptado |
0.913 |
0.855 |
0.852 |
|
CD8 |
SMOTE RSB* Adaptado |
0.937 |
0.906 |
0.900 |
|
CD9 |
SMOTE RSB* Adaptado |
1.000 |
0.946 |
0.944 |
|
CD10 |
Sobremuestreo Aleatorio |
0.945 |
0.884 |
0.884 |
Generación de Datos Sintéticos:
Métodos Utilizados:
- SMOTE RSB* Adaptado con Ruido Gaussiano.
- CTGAN.
Tabla 3. Técnica de Generación de Datos Sintéticos Óptima y su Rendimiento para el Conjunto de Datos Sintético de "Mejor Fidelidad".
|
Conjunto de Datos |
Técnica de Generación de Datos Sintéticos Óptima |
AUC-ROC |
F1-score |
Accuracy |
|
CD1 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.990 |
0.929 |
0.927 |
|
CD2 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.970 |
0.963 |
0.963 |
|
CD3 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.971 |
0.928 |
0.927 |
|
CD4 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
1.000 |
1.000 |
1.000 |
|
CD5 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.949 |
0.798 |
0.808 |
|
CD6 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.974 |
0.922 |
0.923 |
|
CD7 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.995 |
0.950 |
0.950 |
|
CD8 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
1.000 |
0.819 |
0.800 |
|
CD9 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
1.000 |
0.946 |
0.944 |
|
CD10 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.987 |
0.882 |
0.884 |
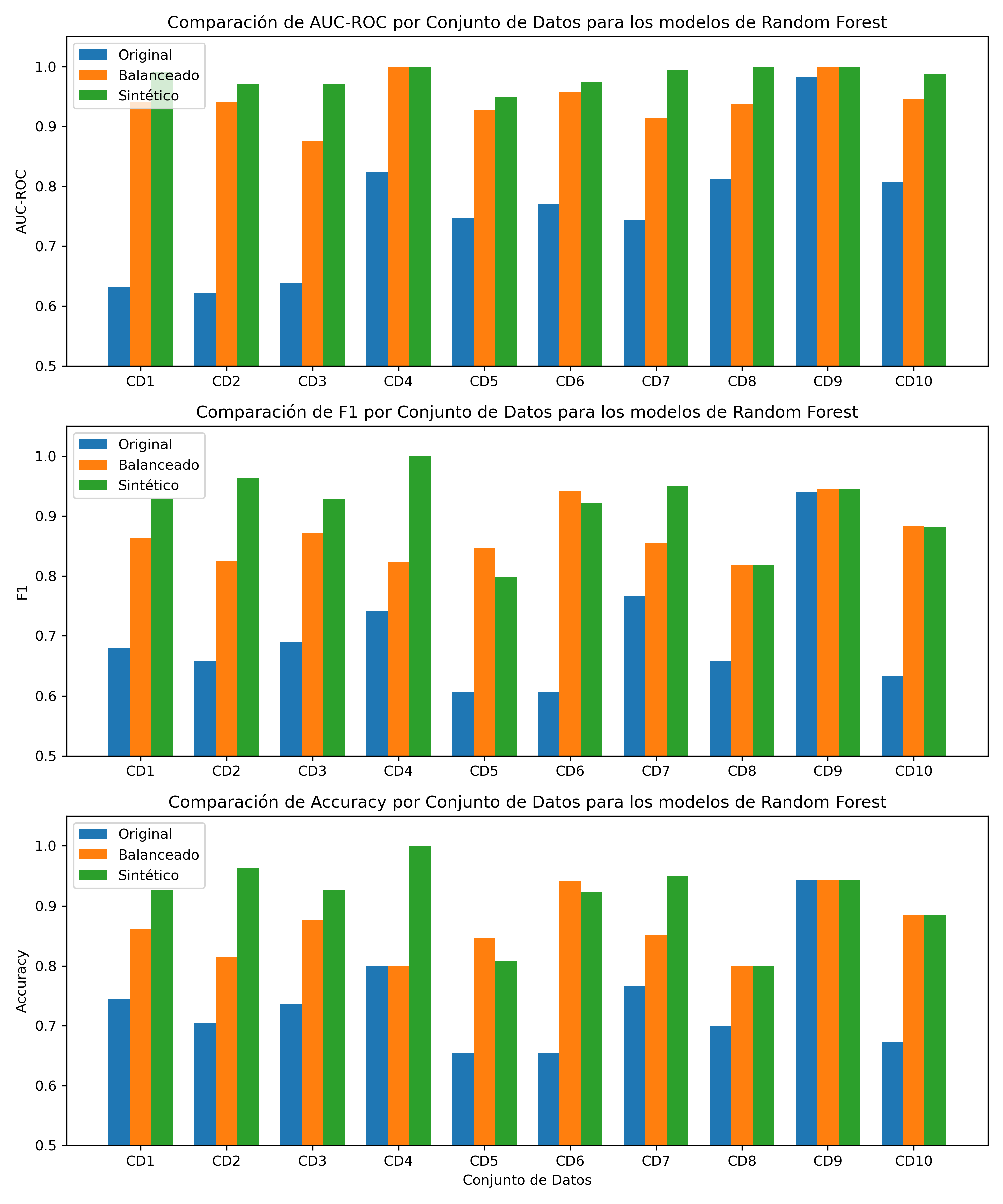
Tabla 4. Rendimiento de cada modelo Random Forest para el conjunto de datos original y su respectivo conjunto de datos balanceado y sintético de “Mejor Fidelidad”.
|
Conjunto de Datos |
Original |
Balanceado de mejor fidelidad |
Sintético de mejor fidelidad |
||||||
|
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
|
|
CD1 |
0.632 |
0.679 |
0.745 |
0.940 |
0.863 |
0.861 |
0.990 |
0.929 |
0.927 |
|
CD2 |
0.622 |
0.658 |
0.704 |
0.940 |
0.825 |
0.815 |
0.970 |
0.963 |
0.963 |
|
CD3 |
0.639 |
0.690 |
0.737 |
0.875 |
0.871 |
0.876 |
0.971 |
0.928 |
0.927 |
|
CD4 |
0.824 |
0.741 |
0.800 |
1.000 |
0.824 |
0.800 |
1.000 |
1.000 |
1.000 |
|
CD5 |
0.747 |
0.606 |
0.654 |
0.927 |
0.847 |
0.846 |
0.949 |
0.798 |
0.808 |
|
CD6 |
0.770 |
0.606 |
0.654 |
0.958 |
0.942 |
0.942 |
0.974 |
0.922 |
0.923 |
|
CD7 |
0.744 |
0.766 |
0.766 |
0.913 |
0.855 |
0.852 |
0.995 |
0.950 |
0.950 |
|
CD8 |
0.813 |
0.659 |
0.700 |
0.938 |
0.819 |
0.800 |
1.000 |
0.819 |
0.800 |
|
CD9 |
0.982 |
0.941 |
0.944 |
1.000 |
0.946 |
0.944 |
1.000 |
0.946 |
0.944 |
|
CD10 |
0.808 |
0.633 |
0.673 |
0.945 |
0.884 |
0.884 |
0.987 |
0.882 |
0.884 |
Fig. 1 - Comparación del desempeño del modelo Random Forest en conjuntos de datos originales, balanceados y sintéticos.
Tabla 5. Rendimiento de cada modelo de Regresión Logística para el conjunto de datos original y su respectivo conjunto de datos balanceado y sintético de “Mejor Fidelidad”.
|
Conjunto de Datos |
Original |
Balanceado de mejor fidelidad |
Sintético de mejor fidelidad |
||||||
|
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
|
|
CD1 |
0.489 |
0.635 |
0.744 |
0.634 |
0.618 |
0.598 |
0.605 |
0.603 |
0.591 |
|
CD2 |
0.401 |
0.602 |
0.685 |
0.713 |
0.723 |
0.685 |
0.698 |
0.67 |
0.629 |
|
CD3 |
0.435 |
0.635 |
0.744 |
0.575 |
0.581 |
0.562 |
0.588 |
0.658 |
0.678 |
|
CD4 |
0.704 |
0.774 |
0.766 |
0.892 |
0.695 |
0.600 |
0.964 |
0.723 |
0.633 |
|
CD5 |
0.747 |
0.546 |
0.615 |
0.739 |
0.754 |
0.750 |
0.759 |
0.683 |
0.673 |
|
CD6 |
0.766 |
0.693 |
0.730 |
0.850 |
0.794 |
0.788 |
0.894 |
0.794 |
0.807 |
|
CD7 |
0.546 |
0.610 |
0.704 |
0.859 |
0.776 |
0.770 |
0.775 |
0.646 |
0.639 |
|
CD8 |
0.687 |
0.638 |
0.600 |
0.583 |
0.450 |
0.600 |
0.666 |
0.703 |
0.700 |
|
CD9 |
0.642 |
0.625 |
0.611 |
0.694 |
0.666 |
0.666 |
0.805 |
0.675 |
0.666 |
|
CD10 |
0.797 |
0.636 |
0.692 |
0.788 |
0.775 |
0.769 |
0.853 |
0.793 |
0.788 |
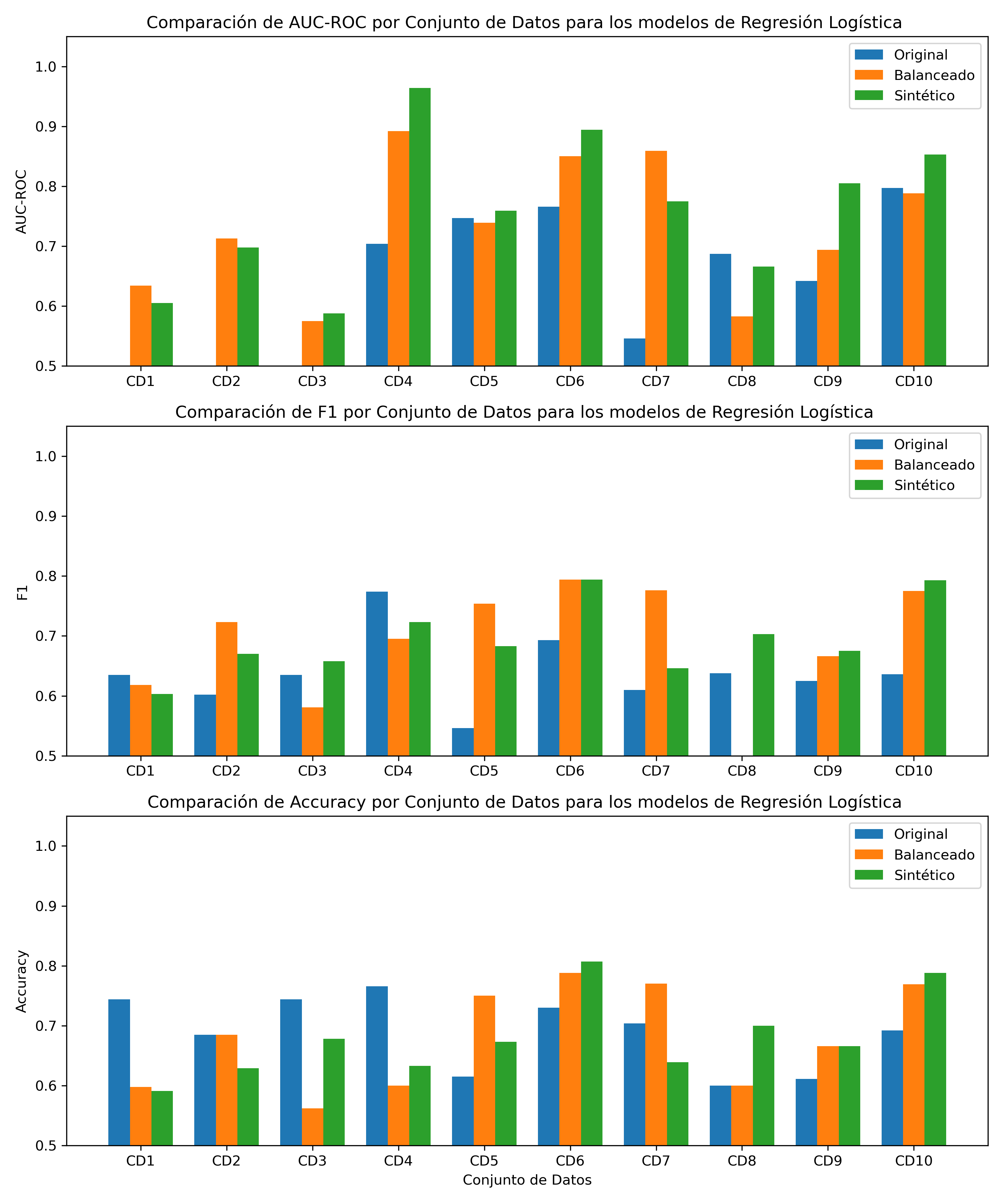
Fig. 2 - Comparación del desempeño del modelo de Regresión Logística en conjuntos de datos originales, balanceados y sintéticos.
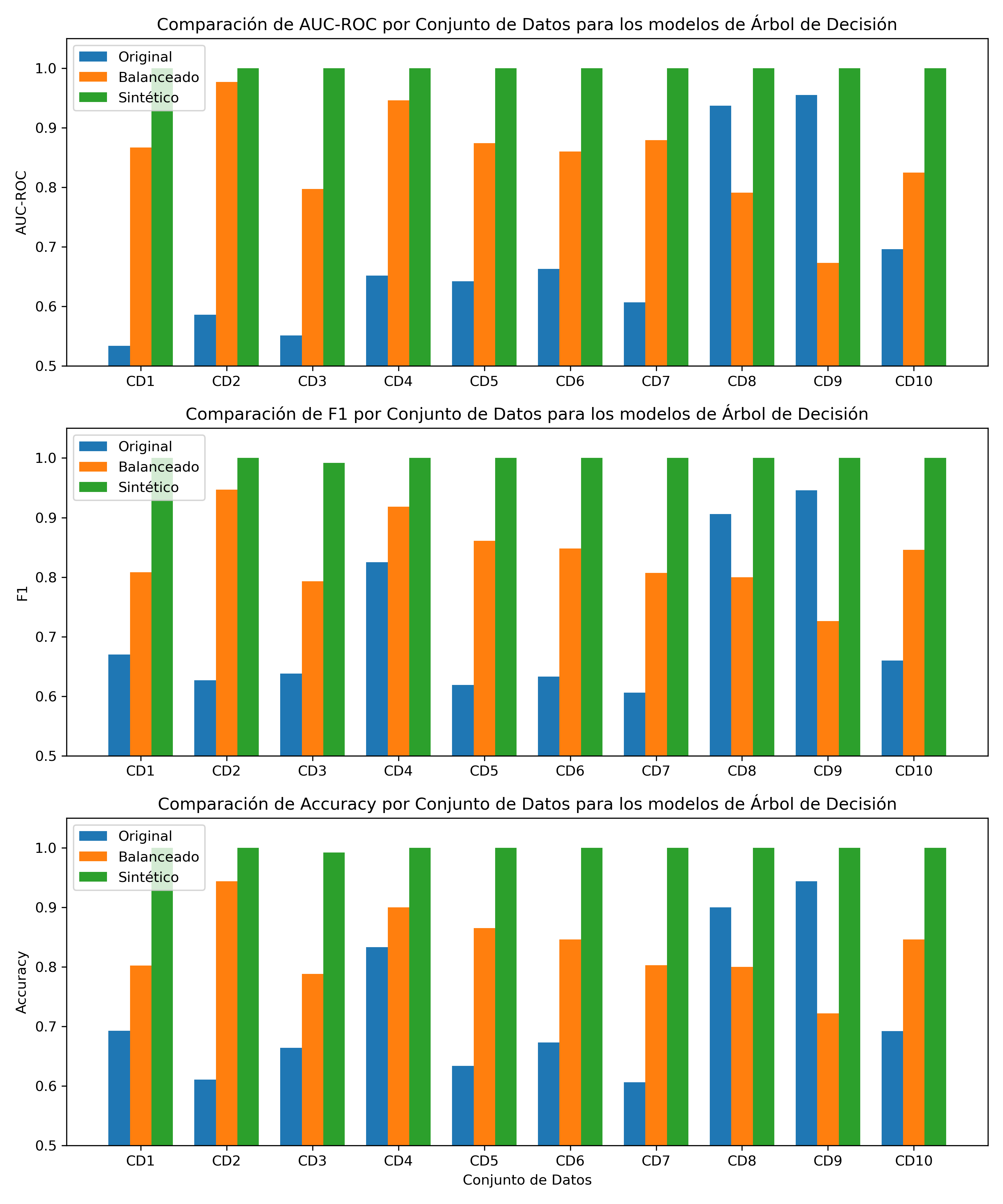
Tabla 6. Rendimiento de cada modelo de Árbol de Decisión para el conjunto de datos original y su respectivo conjunto de datos balanceado y sintético de “Mejor Fidelidad”.
|
Conjunto de Datos |
Original |
Balanceado de mejor fidelidad |
Sintético de mejor fidelidad |
||||||
|
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
|
|
CD1 |
0.534 |
0.670 |
0.693 |
0.867 |
0.808 |
0.802 |
1.000 |
1.000 |
1.000 |
|
CD2 |
0.586 |
0.627 |
0.611 |
0.977 |
0.947 |
0.944 |
1.000 |
1.000 |
1.000 |
|
CD3 |
0.551 |
0.638 |
0.664 |
0.797 |
0.793 |
0.788 |
1.000 |
0.992 |
0.992 |
|
CD4 |
0.652 |
0.825 |
0.833 |
0.946 |
0.918 |
0.900 |
1.000 |
1.000 |
1.000 |
|
CD5 |
0.642 |
0.619 |
0.634 |
0.874 |
0.861 |
0.865 |
1.000 |
1.000 |
1.000 |
|
CD6 |
0.663 |
0.633 |
0.673 |
0.860 |
0.848 |
0.846 |
1.000 |
1.000 |
1.000 |
|
CD7 |
0.607 |
0.606 |
0.606 |
0.879 |
0.807 |
0.803 |
1.000 |
1.000 |
1.000 |
|
CD8 |
0.937 |
0.906 |
0.900 |
0.791 |
0.800 |
0.800 |
1.000 |
1.000 |
1.000 |
|
CD9 |
0.955 |
0.946 |
0.944 |
0.673 |
0.726 |
0.722 |
1.000 |
1.000 |
1.000 |
|
CD10 |
0.696 |
0.660 |
0.692 |
0.825 |
0.846 |
0.846 |
1.000 |
1.000 |
1.000 |
Fig. 3 - Comparación del desempeño del modelo de Árbol de Decisión en conjuntos de datos originales, balanceados y sintéticos.
Tabla 7. Rendimiento de cada modelo de Máquina de Vector de Soporte para el conjunto de datos original y su respectivo conjunto de datos balanceado y sintético de “Mejor Fidelidad”.
|
Conjunto de Datos |
Original |
Balanceado de mejor fidelidad |
Sintético de mejor fidelidad |
||||||
|
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
|
|
CD1 |
0.549 |
0.628 |
0.708 |
0.544 |
0.599 |
0.678 |
0.544 |
0.599 |
0.678 |
|
CD2 |
0.467 |
0.633 |
0.648 |
0.259 |
0.757 |
0.833 |
0.259 |
0.757 |
0.833 |
|
CD3 |
0.553 |
0.617 |
0.708 |
0.554 |
0.640 |
0.729 |
0.554 |
0.640 |
0.729 |
|
CD4 |
0.496 |
0.757 |
0.833 |
0.517 |
0.842 |
0.800 |
0.517 |
0.842 |
0.800 |
|
CD5 |
0.315 |
0.422 |
0.576 |
0.642 |
0.603 |
0.653 |
0.642 |
0.603 |
0.653 |
|
CD6 |
0.728 |
0.649 |
0.692 |
0.744 |
0.743 |
0.750 |
0.744 |
0.743 |
0.750 |
|
CD7 |
0.525 |
0.606 |
0.606 |
0.608 |
0.661 |
0.688 |
0.608 |
0.661 |
0.688 |
|
CD8 |
0.125 |
0.711 |
0.800 |
0.458 |
0.640 |
0.700 |
0.458 |
0.640 |
0.700 |
|
CD9 |
0.660 |
0.582 |
0.555 |
0.486 |
0.533 |
0.666 |
0.486 |
0.533 |
0.666 |
|
CD10 |
0.287 |
0.649 |
0.692 |
0.690 |
0.647 |
0.653 |
0.690 |
0.647 |
0.653 |
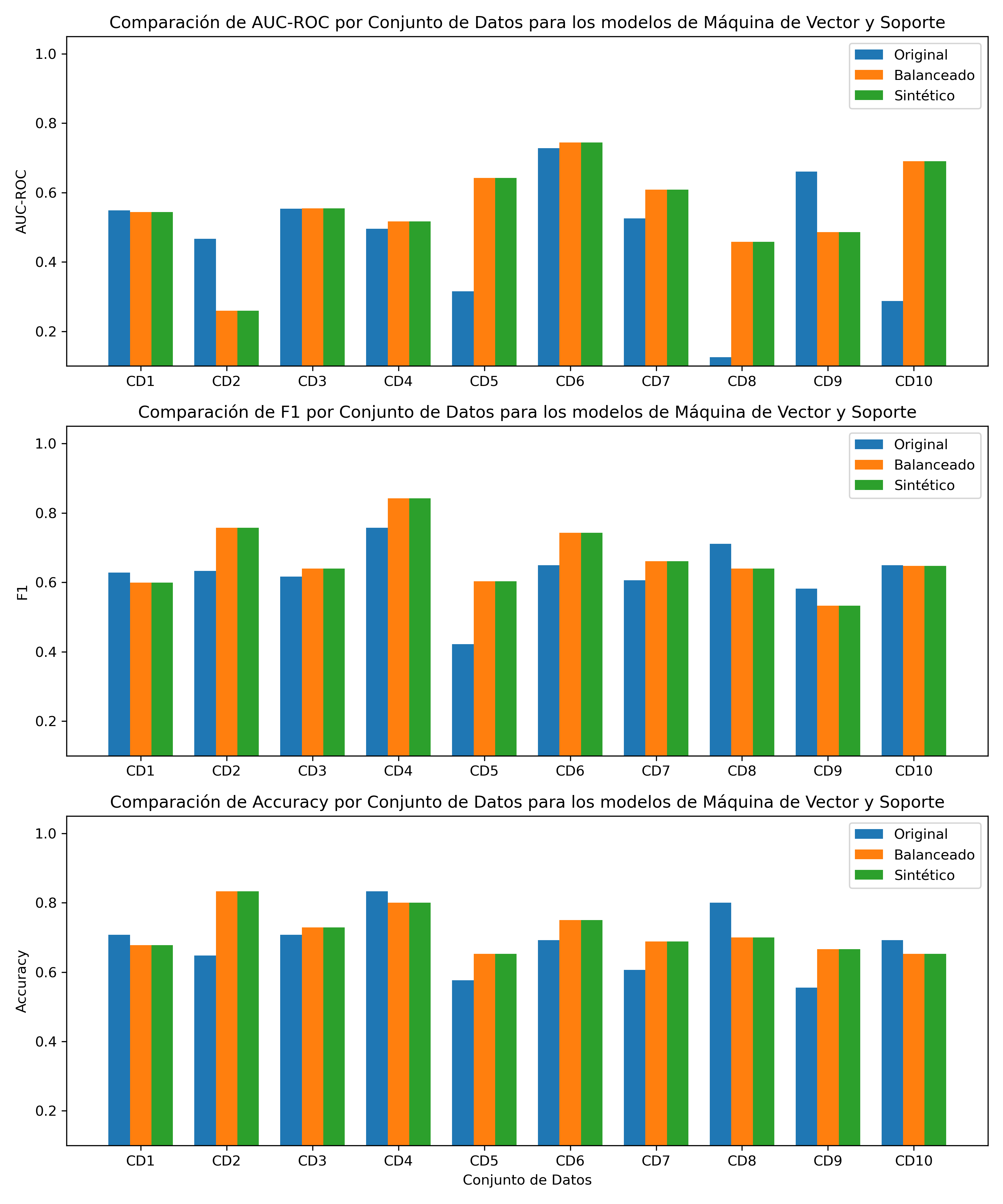
Fig. 4 - Comparación del desempeño del modelo de Máquina de Vector de Soporte en conjuntos de datos originales, balanceados y sintéticos.
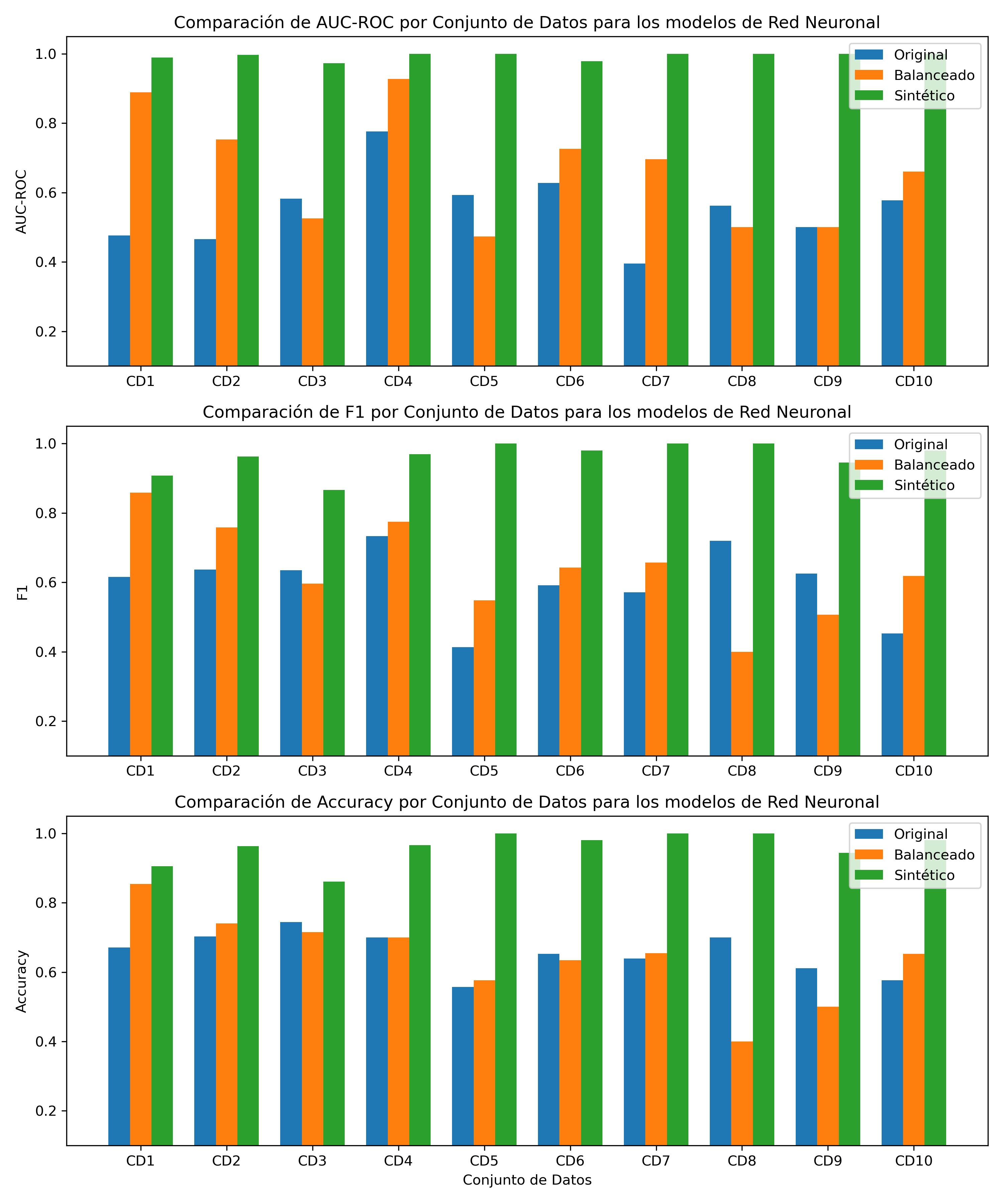
Tabla 8. Rendimiento de cada modelo de Red Neuronal para el conjunto de datos original y su respectivo conjunto de datos balanceado y sintético de “Mejor Fidelidad”.
|
Conjunto de Datos |
Original |
Balanceado de mejor fidelidad |
Sintético de mejor fidelidad |
||||||
|
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
|
|
CD1 |
0.476 |
0.616 |
0.671 |
0.889 |
0.859 |
0.854 |
0.989 |
0.908 |
0.905 |
|
CD2 |
0.466 |
0.637 |
0.703 |
0.753 |
0.758 |
0.740 |
0.997 |
0.963 |
0.963 |
|
CD3 |
0.582 |
0.635 |
0.744 |
0.525 |
0.596 |
0.715 |
0.973 |
0.866 |
0.861 |
|
CD4 |
0.776 |
0.733 |
0.700 |
0.928 |
0.775 |
0.700 |
1.000 |
0.969 |
0.966 |
|
CD5 |
0.593 |
0.413 |
0.557 |
0.473 |
0.548 |
0.576 |
1.000 |
1.000 |
1.000 |
|
CD6 |
0.628 |
0.591 |
0.653 |
0.726 |
0.643 |
0.634 |
0.979 |
0.980 |
0.980 |
|
CD7 |
0.395 |
0.571 |
0.639 |
0.696 |
0.657 |
0.655 |
1.000 |
1.000 |
1.000 |
|
CD8 |
0.562 |
0.720 |
0.700 |
0.500 |
0.400 |
0.400 |
1.000 |
1.000 |
1.000 |
|
CD9 |
0.500 |
0.625 |
0.611 |
0.500 |
0.507 |
0.500 |
1.000 |
0.945 |
0.944 |
|
CD10 |
0.578 |
0.453 |
0.576 |
0.660 |
0.618 |
0.653 |
1.000 |
0.980 |
0.980 |
Fig. 5 - Comparación del desempeño del modelo de Red Neuronal en conjuntos de datos originales, balanceados y sintéticos.
Resultados:
Los resultados demuestran que TabDSFidelity puede guiar la selección de datos sintéticos que mejoran el rendimiento de los modelos de clasificación, aunque la magnitud y la naturaleza de la mejora varían según el algoritmo.
- Modelos de Árboles (Árbol de Decisión y Random Forest): Muestran mejoras sustanciales en todas las métricas, aumento promedio del 32.02% en el AUC-ROC, 32.46% en el F1-score y 24.63% en el Accuracy para el modelo de Random Forest y aumento promedio de 51.92% en el AUC-ROC, 43.76% en el F1-score y 41.03% en el Accuracy para el modelo de Árbol de Decisión, lo que sugiere que TabDSFidelity es efectiva para seleccionar datos sintéticos que mejoran significativamente el rendimiento predictivo de estos modelos.
- Red Neuronal: Muestra las mayores mejoras promedio en AUC-ROC, F1-score y Accuracy, aumento promedio de 84.64% en el AUC-ROC, 65.67% en el F1-score y 47.92% en el Accuracy, indicando que estos modelos complejos pueden beneficiarse enormemente de la selección de datos basada en TabDSFidelity.
- Regresión Logística: Mejora el AUC-ROC, mejoras menores en F1-score y una ligera disminución en la Accuracy, aumento promedio de 25.95% en el AUC-ROC, 9.17% en el F1-score y una disminución promedio de 0.47% en el Accuracy, lo que sugiere que es posible que los datos sintéticos no se traduzcan directamente en un mejor rendimiento para este modelo.
- SVM: La mejora en AUC-ROC es destacable, pero el bajo impacto en F1-score y Accuracy, aumento promedio de 46.12% en el AUC-ROC, 7.77% en el F1-score y 6.05% en el Accuracy, sugiere que, aunque los datos sintéticos mejoran la capacidad de discriminación de los modelos SVM, podrían no mejorar su capacidad de generalización o su precisión general.
Relación entre TabDSFidelity y el Rendimiento de los Modelos de Clasificación:
Específicamente, se encontró una correlación positiva de moderada a fuerte entre TabDSFidelity y AUC-ROC (rho = 0.662, p < 0.001), entre TabDSFidelity y F1-score (rho=0.682, p < 0.001), y entre TabDSFidelity y Accuracy (rho=0.660, p < 0.001). Estos resultados sugieren que, en general, una TabDSFidelity más alta tiende a estar asociada con un mejor rendimiento del clasificador.
El alto significado estadístico (p < 0.001) de estas correlaciones indica que es muy poco probable que la relación observada se deba al azar, lo que fortalece la validez de TabDSFidelity como un índice que, en su diseño, prioriza el rendimiento predictivo al evaluar la calidad de los datos.
Análisis de sensibilidad de las ponderaciones de TabDSFidelity:
| Conjunto de Datos | Ponderación que prioriza la efectividad predictiva | Ponderación equilibrada | Ponderación que prioriza la fidelidad estadística | |||
|---|---|---|---|---|---|---|
| Balanceo | Generación Sintética | Balanceo | Generación Sintética | Balanceo | Generación Sintética | |
| CD1 | SMOTE RSB* Adaptado | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | SMOTE RSB* Adaptado | SMOTE RSB* con Ruido Gaussiano |
| CD2 | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | SMOTE RSB* Adaptado | SMOTE RSB* con Ruido Gaussiano | SMOTE RSB* Adaptado | SMOTE RSB* con Ruido Gaussiano |
| CD3 | SMOTE RSB* Adaptado | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano |
| CD4 | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano |
| CD5 | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano |
| CD6 | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano |
| CD7 | SMOTE RSB* Adaptado | SMOTE RSB* con Ruido Gaussiano | BorderLine-SMOTE | SMOTE RSB* con Ruido Gaussiano | SMOTE RSB* Adaptado | SMOTE RSB* con Ruido Gaussiano |
| CD8 | SMOTE RSB* Adaptado | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano |
| CD9 | SMOTE RSB* Adaptado | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | SMOTE RSB* Adaptado | SMOTE RSB* con Ruido Gaussiano |
| CD10 | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano | Random OverSampling | SMOTE RSB* con Ruido Gaussiano |

Autores de la Investigación
- Autor (es) : MSc. Marcos Díaz Bastida
- : Dr. C. Ramiro A. Pérez Vázquez
- : Dr. C. Rafael Bello Pérez
- Colaborador (es) : Dr. C. Armando Caballero López
- : MSc. Armando Caballero Font