Metodología para la Generación y Evaluación de Datos Sintéticos Tabulares: Metodología TDS.
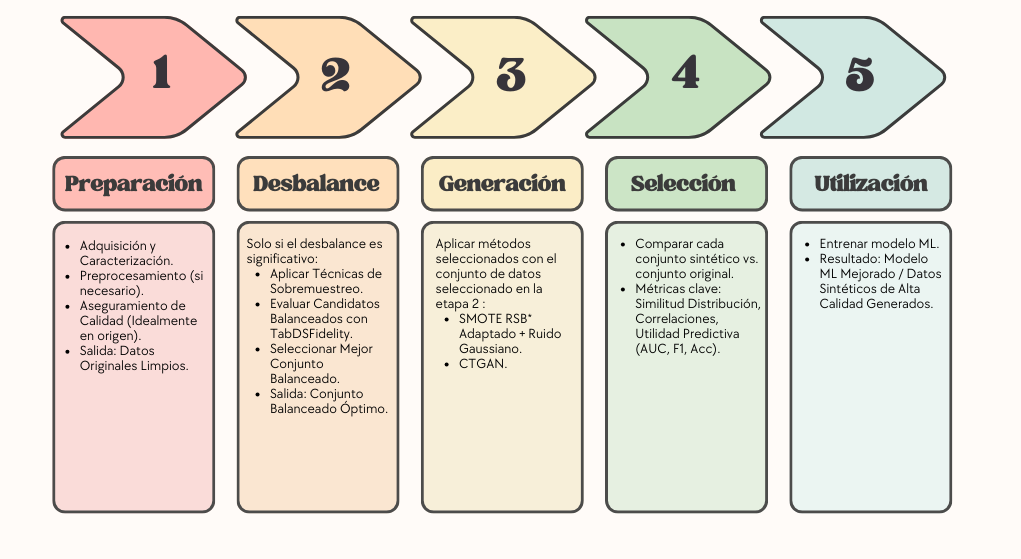
Este trabajo propone una metodología para generar y evaluar datos sintéticos tabulares, especialmente a partir de conjuntos desbalanceados, ilustrada con un caso de estudio en Unidades de Cuidados Intensivos. La metodología comprende: (1) balanceo de clases mediante sobremuestreo, seleccionando la mejor técnica con una función de calidad; (2) generación de datos sintéticos a partir del conjunto balanceado óptimo, utilizando SMOTE RSB* Adaptado con Ruido Gaussiano y CTGAN; y (3) una función de calidad novedosa, "TabDSFidelity", que integra s imilitud de distribución, preservación de correlaciones y utilidad predictiva para guiar la selección en cada etapa. Aplicada a diez conjuntos de datos, la metodología demostró que el uso de datos sintéticos seleccionados por una función de calidad mejora significativamente el rendimiento de modelos de clasificación comparado con el empleo solamente de los datos originales. SMOTE RSB* Adaptado con Ruido Gaussiano generó de manera consistente los datos de mayor calidad según TabDSFidelity en este estudio. Se concluye que la metodología propuesta ofrece un marco eficaz para mitigar la escasez y el desbalance de datos, facilitando la creación de modelos más precisos y robustos.
Conjuntos de Datos:
Los datos originales utilizados en este estudio fueron obtenidos a través de una aplicación web denominada "Generador de Conjuntos de Datos Dinámicos para el Servicio de Terapia Intensiva". Esta aplicación está diseñada para almacenar y gestionar información detallada de pacientes ingresados en Unidades de Cuidados Intensivos (UCI), permitiendo a los investigadores construir conjuntos de datos personalizados adaptados a sus necesidades específicas. Se generaron diez conjuntos de datos distintos (CD1 a CD10), cada uno correspondiente a una condición médica específica de pacientes ingresados en la UCI:
- CD1: Neumonía Grave Adquirida en la Comunidad.
- CD2: Enfermedad Pulmonar Obstructiva Crónica (EPOC) Exacerbada por Infección Respiratoria.
- CD3: Neumonía Nosocomial.
- CD4: Cetoacidosis Diabética.
- CD5: Contusión Cerebral.
- CD6: Hemorragia Subaracnoidea (HSA) Postraumática.
- CD7: Infección Urinaria.
- CD8: Meningoencefalitis Bacteriana.
- CD9: Síndrome de Weil.
- CD10: SPO de craniectomía y evacuación de Hematoma subdural.
Tabla 1. Características de los Conjuntos de Datos Originales del Caso de Estudio (UCI).
|
Conjunto de Datos |
No. de Ejem. |
No. de Atrib. |
No. Atrib. Cat. |
Proporción Clase Positiva ("Fallecido" = 1) |
Proporción de Desbalance |
Tipo de Desbalance |
|
CD1 |
548 |
24 |
20 |
0.30 |
2.36 |
Mínimo |
|
CD2 |
216 |
26 |
22 |
0.17 |
4.68 |
Severo |
|
CD3 |
548 |
21 |
17 |
0.30 |
2.36 |
Mínimo |
|
CD4 |
117 |
26 |
20 |
0.12 |
6.80 |
Severo |
|
CD5 |
206 |
20 |
16 |
0.32 |
2.12 |
Mínimo |
|
CD6 |
206 |
39 |
35 |
0.32 |
2.12 |
Mínimo |
|
CD7 |
239 |
33 |
29 |
0.37 |
1.68 |
Mínimo |
|
CD8 |
39 |
24 |
20 |
0.25 |
2.90 |
Mínimo |
|
CD9 |
69 |
34 |
30 |
0.26 |
2.83 |
Mínimo |
|
CD10 |
206 |
46 |
42 |
0.32 |
2.12 |
Mínimo |
|
Promedio Aproximado |
239 |
29 |
25 |
0.27 |
2.99 |
Mínimo |
Técnicas de Balanceo Empleadas:
- Random Oversampling: es una técnica de sobremuestreo que busca aumentar artificialmente el número de casos de la clase minoritaria a través de la replicación aleatoria de algunos de sus ejemplos existentes. En esencia, esta técnica aumenta el número de ejemplos de la clase menos representada hasta que iguala o supera el número de ejemplos de la clase mayoritaria.
- SMOTE (Synthetic Minority Oversampling Technique): técnica avanzada para tratar el desbalance de clases en problemas de clasificación, generando casos sintéticos de la clase minoritaria en lugar de simplemente replicar las existentes, como Random Oversampling. Este método identifica los casos de la clase minoritaria y calcula las distancias a sus vecinos más cercanos dentro de la misma clase, seleccionando un conjunto de estos vecinos para cada caso. Luego, genera nuevos ejemplos mediante interpolación, creando puntos intermedios entre los casos originales y sus vecinos seleccionados. Este proceso enriquece el conjunto de datos con ejemplos que representan mejor la variabilidad de la clase minoritaria, mejorando la generalización del modelo. Finalmente, el nuevo conjunto de datos combina estos ejemplos sintéticos con las originales de ambas clases, logrando un equilibrio que favorece el rendimiento en modelos de aprendizaje automático.
- Borderline SMOTE: es una variante de SMOTE que se centra en los casos de la clase minoritaria que están cerca del límite de decisión, es decir, las que tienen más probabilidad de ser clasificadas incorrectamente. Genera casos sintéticos únicamente en esta región para mejorar la separación entre clases y reducir el riesgo de confusión entre ellas.
- ADASYN (Adaptive Synthetic Sampling Approach): ADASYN es una variante de SMOTE, que a diferencia de SMOTE estándar, genera más casos sintéticos para las regiones donde los casos de la clase minoritaria son más difíciles de clasificar. Esto se logra ajustando la cantidad de ejemplos generados de manera adaptativa, en función de la distribución local y la dificultad percibida.
- SMOTE RSB* Adaptado con Restricciones del Dominio: Esta técnica de sobremuestreo, adaptación de SMOTE RSB*, que incorpora restricciones específicas del dominio médico para garantizar que los ejemplos sintéticos generados sean realistas y coherentes con el conocimiento clínico. A diferencia de las técnicas de sobremuestreo convencionales, que generan ejemplos sintéticos sin tener en cuenta las relaciones y restricciones entre las variables, esta adaptación de SMOTE utiliza reglas y límites definidos para guiar el proceso de generación de datos.
Tabla 2. Puntuaciones TabDSFidelity para Conjuntos de Datos Sobremuestreados (por Técnica y CD Original).
|
Conjunto de Datos |
Sobremuestreo Aleatorio |
SMOTE |
Borderline SMOTE |
ADASYN |
SMOTE RSB* Adaptado |
Técnica Seleccionada |
Puntuación TabDSFidelity |
|
CD1 |
11.55 |
14.32 |
0.64 |
6.18 |
13.07 |
SMOTE |
14.32 |
|
CD2 |
12.99 |
9.72 |
9.89 |
16.85 |
2.88 |
ADASYN |
16.85 |
|
CD3 |
6.47 |
10.89 |
0.69 |
13.95 |
13.17 |
ADASYN |
13.95 |
|
CD4 |
13.84 |
5.27 |
13.58 |
15.52 |
4.65 |
ADASYN |
15.52 |
|
CD5 |
6.99 |
14.53 |
13.89 |
0.77 |
18.04 |
SMOTE RSB* Adaptado |
18.04 |
|
CD6 |
18.69 |
15.53 |
11.68 |
6.55 |
2.58 |
Sobremuestreo Aleatorio |
18.69 |
|
CD7 |
8.13 |
9.62 |
17.58 |
5.11 |
3.49 |
Borderline Smote |
17.58 |
|
CD8 |
14.76 |
11.69 |
11.69 |
2 |
16.44 |
SMOTE RSB* Adaptado |
16.44 |
|
CD9 |
17.85 |
8.40 |
1.92 |
11.56 |
6.15 |
Sobremuestreo Aleatorio |
17.85 |
|
CD10 |
12.31 |
4.76 |
3.83 |
1.98 |
17.61 |
SMOTE RSB* Adaptado |
17.61 |
Tabla 3. Características de los Conjuntos de Datos Sobremuestreados Seleccionados en el Caso de Estudio.
|
Conjunto de Datos |
Técnica de Sobremuestreo Seleccionada |
Número de Ejemplos Clase Positiva ("Fallecido" = 1) |
Número de Ejemplos Clase Negativa ("Fallecido" = 0) |
Proporción de Desbalance |
|
CD1 |
SMOTE |
289 |
289 |
1.00 |
|
CD2 |
ADASYN |
125 |
133 |
1.06 |
|
CD3 |
ADASYN |
290 |
289 |
1.00 |
|
CD4 |
ADASYN |
79 |
76 |
1.03 |
|
CD5 |
SMOTE RSB* Adaptado |
98 |
105 |
1.07 |
|
CD6 |
Sobremuestreo Aleatorio |
105 |
105 |
1.00 |
|
CD7 |
Borderline Smote |
114 |
114 |
1.00 |
|
CD8 |
SMOTE RSB* Adaptado |
21 |
22 |
1.04 |
|
CD9 |
Sobremuestreo Aleatorio |
38 |
38 |
1.00 |
|
CD10 |
SMOTE RSB* Adaptado |
98 |
105 |
1.07 |
Generación de Datos Sintéticos:
Enfoque 1 (SMOTE RSB* Adaptado + Ruido Gaussiano):
Entrada:
D_orig: Conjunto de datos original (Dataset tabular).
N_total: Número total de muestras sintéticas a generar.
Constraints: Estructura de datos con restricciones del dominio (límites numéricos, valores categóricos permitidos, escalas de ruido, probabilidad de cambio).
Proportions: Diccionario con proporciones de N_total para cada técnica {Noise, Interpolation, Variation}.
TargetCol, ApacheCol: Nombres de columnas específicas necesarias para la lógica de variación.
Salida:
D_ synthetic: Muestras sintéticas. D_augmented: Conjunto de datos combinado (D_orig + D_ synthetic).
Procedimiento:
1. // Inicialización
2. NumCols, BinCols ← Identificar_Columnas_Por_Tipo(D_orig, TargetCol)
3. N_noise ← int(N_total * Proportions.Noise)
4. N_interp ← int(N_total * Proportions.Interpolation)
5. N_var ← int(N_total * Proportions.Variation)
6. // Generación por Técnicas Separadas
7. Synth_Noise ← Generar_Via_Ruido_Gaussiano(D_orig, N_noise, NumCols, Constraints)
o (Aplica ruido gaussiano controlado a copias de filas existentes, respeta límites)
8. Synth_Interp ← Generar_Via_Interpolacion_Adaptada(D_orig, N_interp, NumCols, Constraints)
o (Interpola entre vecinos cercanos, aplica límites y reglas de dominio)
9. Synth_Var ← Generar_Via_Variacion_Categorica(D_orig, N_var, BinCols, TargetCol, ApacheCol, Constraints)
o (Modifica probabilísticamente variables binarias/categóricas, usando lógica específica y valores permitidos)
10. // Combinación y Post-procesamiento Final
11. D_synthetic_combined ← Concatenar(Synth_Noise, Synth_Interp, Synth_Var)
12. D_synthetic_combined ← Aplicar_Restricciones_Globales(D_synthetic_combined, NumCols, Constraints.NumLimits)
o (Asegura que todas las filas sintéticas respeten límites finales, ej., Edad, Tiempo de Ventilación)
13. D_augmented ← Concatenar(D_orig, D_synthetic_combined)
14. // Opcional: Guardar Resultados
15. Guardar_Archivo(D_synthetic_combined, ruta_archivo_sintetico_solo)
16. Guardar_Archivo(D_augmented, ruta_archivo_combinado)
17. RETORNAR D_augmented, D_synthetic_combined
Enfoque 2 (CTGAN):
Entrada:
D_orig: Conjunto de datos original (DataFrame tabular).
NumCols, CatCols: Identificación de columnas numéricas y categóricas.
Hyperparams: Estructura de datos con hiperparámetros para CTGAN.
N_synth: Número deseado de muestras sintéticas a generar.
Salida:
D_synth: Conjunto de datos sintético generado y finalizado. D_augmented: Conjunto de datos combinado (D_orig + D_synth).
Procedimiento:
1. D_orig_copy ← Guardar_Copia(D_orig) // Preservar original no transformado
2. // Preprocesamiento (modifica D_orig en una copia de trabajo)
3. D_proc, PreprocessingModels ← Preparar_Datos_Para_CTGAN(D_orig, NumCols, CatCols)
o (Imputación de faltantes en CatCols, conversión de tipos, transformaciones y escalado de NumCols)
4. // Entrenamiento del Modelo CTGAN
5. Model_CTGAN ← Inicializar_Modelo_CTGAN(Hyperparams)
6. Model_CTGAN ← Entrenar(Model_CTGAN, D_proc, CatCols)
7. // Generación de Muestras Sintéticas
8. D_synth_raw ← Muestrear(Model_CTGAN, N_synth)
9. // Postprocesamiento de Datos Sintéticos
10. D_synth ← Finalizar_Datos_Sintéticos(D_synth_raw, NumCols, PreprocessingModels)
o (Aplicar transformaciones inversas, redondear a entero, aplicar límite inferior a NumCols)
11. // Combinación con Datos Originales
12. D_augmented ← Concatenar(D_orig_copy, D_synth) // Combina la copia original con el sintético finalizado
13. // Opcional: Guardar Resultados
14. Guardar_Archivo(D_synth, ruta_archivo_sintetico)
15. Guardar_Archivo(D_augmented, ruta_archivo_combinado)
16. RETORNAR D_synth, D_augmented
Tabla 4. Selección del Método Óptimo de Generación Sintética y Características del Conjunto Sintético de "Mejor Fidelidad" (Evaluado con TabDSFidelity).
|
Conjunto de Datos |
Técnica de Generación de Datos Sintéticos Óptima |
AUC-ROC |
F1-score |
Accuracy |
TabDSFidelity |
|
CD1 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.748 |
0.715 |
0.722 |
19.817 |
|
CD2 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.770 |
0.836 |
0.833 |
19.940 |
|
CD3 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.675 |
0.679 |
0.686 |
19.777 |
|
CD4 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.908 |
0.877 |
0.866 |
18.042 |
|
CD5 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.652 |
0.696 |
0.692 |
19.860 |
|
CD6 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.621 |
0.603 |
0.634 |
18.223 |
|
CD7 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.866 |
0.731 |
0.737 |
19.931 |
|
CD8 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.809 |
0.800 |
0.800 |
19.997 |
|
CD9 |
TVAE |
0.861 |
0.888 |
0.888 |
17.452 |
|
CD10 |
SMOTE RSB* Adaptado con Ruido Gaussiano |
0.676 |
0.670 |
0.673 |
18.326 |
Tabla 5. Rendimiento Comparativo del Modelo de Red Neuronal (Original vs. Mejor Balanceado vs. Mejor Sintético).
|
Conjunto de Datos |
Original |
Balanceado de mejor fidelidad |
Sintético de mejor fidelidad |
||||||
|
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
AUC-ROC |
F1 |
Accuracy |
|
|
CD1 |
0.429 |
0.585 |
0.671 |
0.521 |
0.572 |
0.562 |
0.696 |
0.629 |
0.620 |
|
CD2 |
0.659 |
0.757 |
0.833 |
0.765 |
0.772 |
0.759 |
0.555 |
0.689 |
0.666 |
|
CD3 |
0.537 |
0.577 |
0.700 |
0.519 |
0.646 |
0.671 |
0.637 |
0.628 |
0.613 |
|
CD4 |
0.692 |
0.773 |
0.733 |
0.692 |
0.851 |
0.833 |
0.903 |
0.851 |
0.833 |
|
CD5 |
0.460 |
0.597 |
0.673 |
0.539 |
0.608 |
0.615 |
0.633 |
0.624 |
0.634 |
|
CD6 |
0.544 |
0.550 |
0.634 |
0.421 |
0.350 |
0.365 |
0.569 |
0.608 |
0.615 |
|
CD7 |
0.583 |
0.458 |
0.541 |
0.587 |
0.591 |
0.590 |
0.727 |
0.702 |
0.704 |
|
CD8 |
0.714 |
0.616 |
0.600 |
0.571 |
0.515 |
0.500 |
0.523 |
0.321 |
0.300 |
|
CD9 |
0.446 |
0.525 |
0.500 |
0.507 |
0.481 |
0.500 |
0.784 |
0.888 |
0.888 |
|
CD10 |
0.510 |
0.492 |
0.576 |
0.482 |
0.492 |
0.576 |
0.571 |
0.586 |
0.576 |
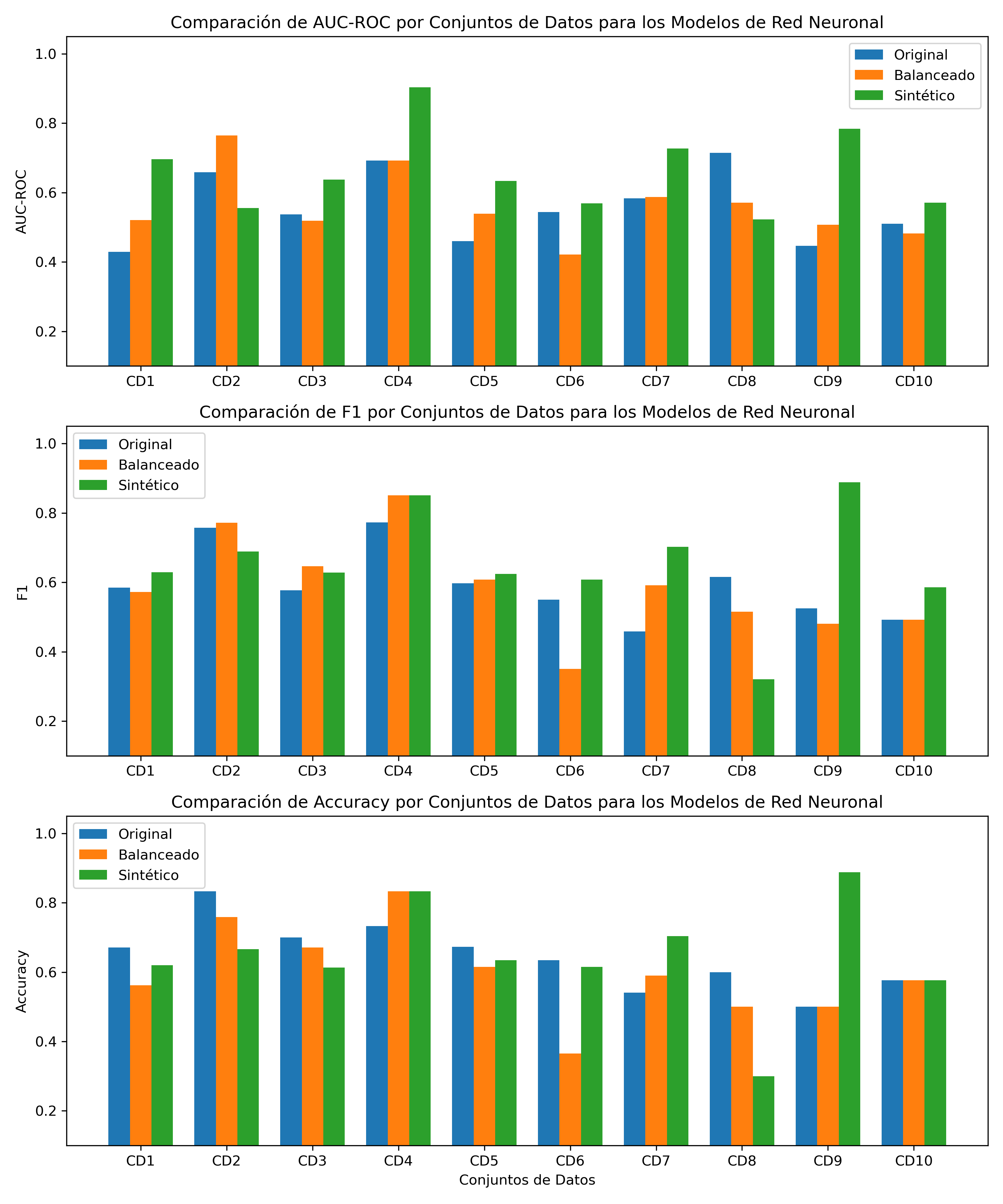
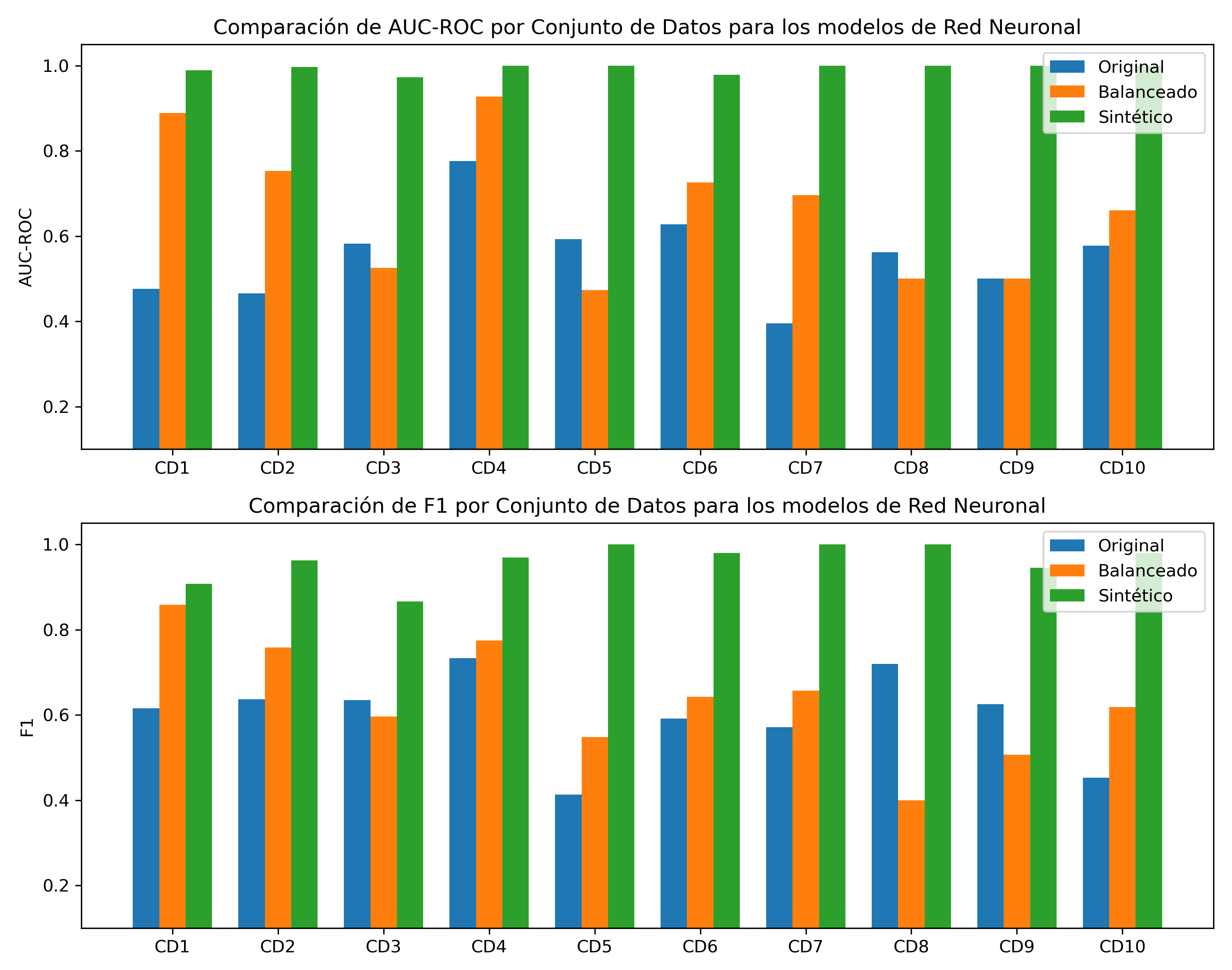
Fig. 1 - Comparación del desempeño del modelo de Red Neuronal en conjuntos de datos originales, balanceados y sintéticos.
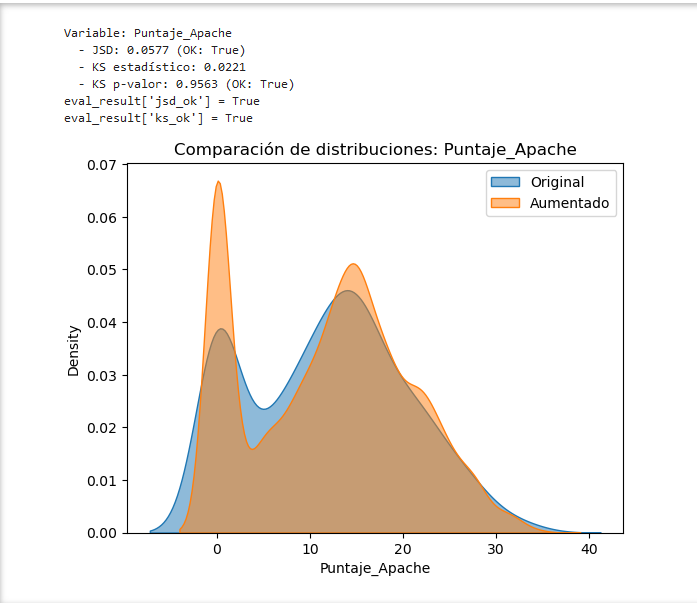
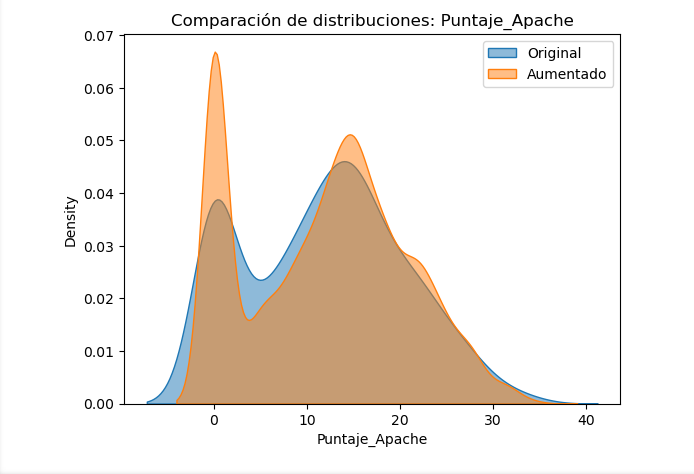
Fig. 2 - Comparación de Distribuciones de la variable “Puntaje Apache”: Datos Originales vs. Sintéticos (CD1, SMOTE RSB* Adaptado con Ruido Gaussiano).
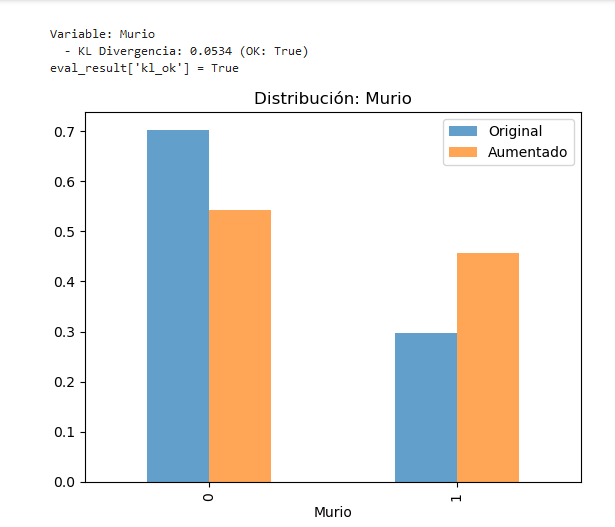
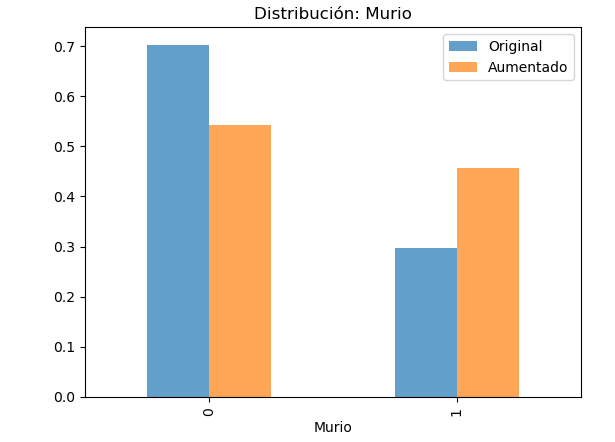
Fig. 3 - Comparación de Distribuciones de la variable “Fallecido”: Datos Originales vs. Sintéticos (CD1, SMOTE RSB* Adaptado con Ruido Gaussiano).
Resultados:
El análisis del impacto en el modelo de clasificación revela la eficacia práctica y los matices de la metodología. El hallazgo principal es la mejora sustancial y promedio en el rendimiento: un aumento del 22.35% en el AUC-ROC mejora el clasificador, que pasa de tener un rendimiento casi aleatorio a ofrecer predicciones con una capacidad de predicción útil y aplicable en la práctica clínica. Sin embargo, un análisis más profundo de los resultados por conjunto de datos es revelador. Mientras que la metodología produjo mejoras drásticas en la mayoría de los casos, se observa una disminución en el rendimiento en dos de los diez conjuntos de datos (CD2 y CD8).

Autores de la Investigación
- Autor (es) : MSc. Marcos Díaz Bastida
- : Dr. C. Ramiro A. Pérez Vázquez
- : Dr. C. Rafael Bello Pérez
- Colaborador (es) : Dr. C. Armando Caballero López
- : MSc. Armando Caballero Font